El otro día analizando un tkproff de una SQL me encontré con los siguientes tiempos, la consulta no era ni mensual, era de unos 20 días aproximadamente
call count cpu elapsed disk query current rows
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Parse 1 0.84 0.84 0 4 0 0
Execute 1 0.00 0.00 0 0 0 0
Fetch 6103 108.37 494.38 304213 3173248 0 91530
------- ------ -------- ---------- ---------- ---------- ---------- ----------
total 6105 109.21 495.23 304213 3173252 0 91530
Misses in library cache during parse: 1
Optimizer mode: ALL_ROWS
Parsing user id: 374
Number of plan statistics captured: 1
Rows (1st) Rows (avg) Rows (max) Row Source Operation
---------- ---------- ---------- ---------------------------------------------------
91530 91530 91530 VIEW (cr=3173248 pr=304213 pw=0 time=94078182 us starts=1 cost=12239 size=670 card=2)
Como podemos observar, el tiempo que tarda en dar respuesta son casi 2 minutos aproximadamente con más de 3.000.000 de bloques leídos.
Si seguimos analizando el árbol de ejecución vemos algo muy extraño
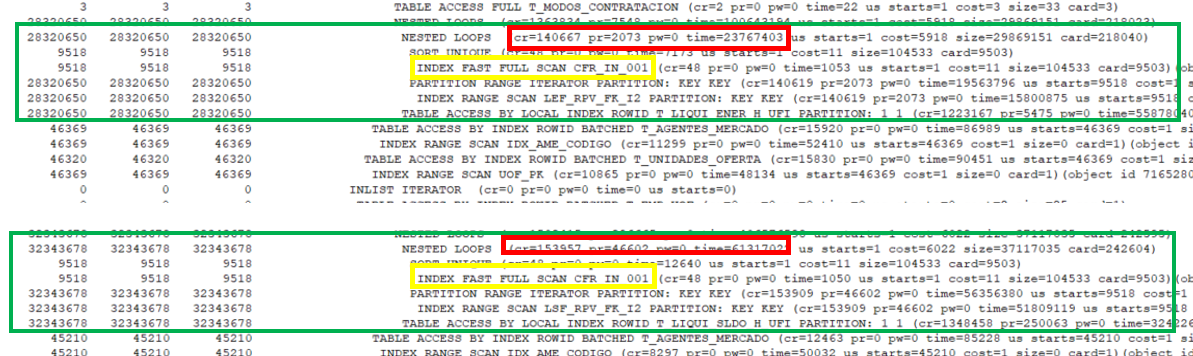
Ambas operaciones NESTED LOOPS son las que están causando la penalización a la hora de obtener buenos tiempos en la ejecución, además ambas operaciones tienen un punto en común, que es CFR_IN_001.
¿Qué tiene la consulta para que este haciendo ese acceso incorrecto? Pues dos clausulas EXISTS usadas erróneamente.
Hay que tener claro una cosa, cuando nosotros tenemos una SELECT que tiene una subconsulta como es nuestro caso, si es una subconsulta "IN" y tenemos que el grueso de la ejecución se lo lleva la SELECT y la subconsulta "IN", tiene poco peso, es decir, que es una consulta ligera, vamos a tener mejor rendimiento utilizando "IN" que utilizando "EXISTS", porque "EXISTS" me va dar un mejor beneficio cuando el grueso de "EXISTS" sea muy grande respecto a una ejecución ligera de la consulta principal.
En este caso, no es necesario aplicar "IN" or "EXISTS", por como esta definida la SQL, con un join debería ser suficiente.
Ejecutamos ahora la consulta, con estos tiempos
call count cpu elapsed disk query current rows
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Parse 2 0.37 0.37 0 0 0 0
Execute 2 0.00 0.00 0 0 0 0
Fetch 7081 8.81 9.24 768 1392473 0 106172
------- ------ -------- ---------- ---------- ---------- ---------- ----------
total 7085 9.19 9.61 768 1392473 0 106172
Misses in library cache during parse: 1
Optimizer mode: ALL_ROWS
Parsing user id: 374
Number of plan statistics captured: 2
Rows (1st) Rows (avg) Rows (max) Row Source Operation
---------- ---------- ---------- ---------------------------------------------------
0 53086 106172 VIEW (cr=696236 pr=384 pw=0 time=1814900 us starts=1 cost=536 size=670 card=2)
La ejecución es inmediata y las operaciones NESTED LOOP ya tienen un tiempo normal
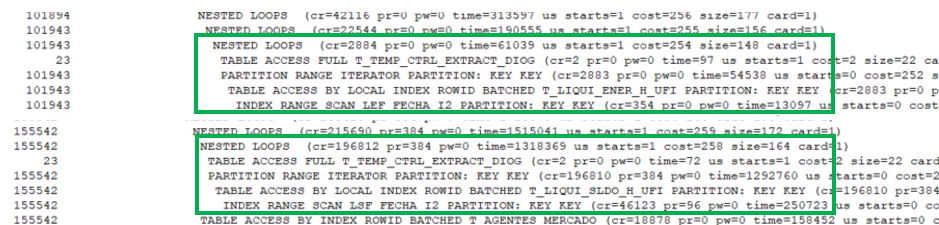
En el siguiente capítulo abordaremos como reducir el número de bloques leídos.

![[26ai] SQL: Calendar functions/Aggregation Filters "CALENDAR"](/_next/image?url=https%3A%2F%2Fcdn.hashnode.com%2Fuploads%2Fcovers%2F65605419d28f19cc44df7ef1%2F587e3328-9877-4c7a-aad7-7811e251f81e.png&w=3840&q=75)
![[OCI] Recreación PDB$SEED](/_next/image?url=https%3A%2F%2Fcdn.hashnode.com%2Fuploads%2Fcovers%2F65605419d28f19cc44df7ef1%2F289ede5b-558c-4f93-b5c0-fa04680c91ca.png&w=3840&q=75)
![[OCI] Clone PDB](/_next/image?url=https%3A%2F%2Fcdn.hashnode.com%2Fuploads%2Fcovers%2F65605419d28f19cc44df7ef1%2F8ce0c665-4a5d-459d-91cf-ffe3f47d8176.png&w=3840&q=75)
![[OCI] Check Jobs DBCli](/_next/image?url=https%3A%2F%2Fcdn.hashnode.com%2Fuploads%2Fcovers%2F65605419d28f19cc44df7ef1%2F1376a869-58fa-491e-926a-a6ead08f9c80.png&w=3840&q=75)
![[26ai] JOIN_TO_ME](/_next/image?url=https%3A%2F%2Fcdn.hashnode.com%2Fuploads%2Fcovers%2F65605419d28f19cc44df7ef1%2F16a23f6e-ec4c-4f0a-9529-2c8a2af2ef5e.png&w=3840&q=75)